Notre offre
Le Machine Learning Operations (MLOps) a pour objectif de normaliser le processus de mise en production des modèles de Machine Learning (ML) puis d’en assurer la maintenance et la supervision. Il est donc nécessaire pour assurer la création, la qualité et le passage à l’échelle des solutions de ML et d’IA. Il permettra aussi de faciliter la collaboration entre les différentes équipes (data scientists, data engineers, ingénieurs ML) et ainsi de gagner en rapidité d’exécution.
Avec la recrudescence du recours à l’IA, maîtriser ce processus devient stratégique. Aujourd’hui le vrai challenge est de construire des systèmes ML intégrés en continu en leur assurant une qualité constante.
Chez Al Switch nous sommes spécialisés dans le MLOps depuis plusieurs années. Nous avons déjà créé des solutions pour de nombreuses entreprises de secteurs variés.
- Accélérer le développement et le déploiement des uses cases IA
- Mettre à l'échelle et gagner en flexibilité
- Améliorer la qualité et la performance du modèle
- Gagner en efficacité opérationnelle et réduire les coûts
Comment assurer la réussite d'un projet MLOps
Continuous training
Cette pratique garantit que les modèles restent performants et adaptés, même face à l’évolution constante des données et des exigences métier. L’emploi de pipelines automatisés pour le training facilite grandement le processus de réentraînement, que ce soit pour intégrer de nouvelles données ou suite à des mises à jour du modèle. Cette approche minimise de manière significative le temps et l’effort requis pour actualiser et optimiser les modèles, assurant ainsi leur fiabilité et leur efficacité à long terme.
Quality evaluation
L’évaluation de la qualité des modèles est fondamentale pour assurer leur efficacité et fiabilité dans un contexte opérationnel. Il est d’usage d’intégrer des étapes dédiées à l’évaluation de la qualité des modèles directement au sein des pipelines d’entraînement, ce qui permet un contrôle qualité continu et systématique des modèles. Pour faciliter le suivi de la performance et la comparaison entre les différentes versions de modèles, l’utilisation d’outils de tracking (MLflow, Weights & Biases…) devient essentielle. Ces outils offrent une vue d’ensemble claire sur les métriques de performance des modèles au fil du temps, aidant ainsi les équipes à identifier rapidement les versions les plus performantes. En adoptant une telle approche, vous parviendrez à maintenir des standards élevés de qualité et de performance pour vos modèles, garantissant ainsi leur pertinence et leur valeur ajoutée opérationnelle.
Data quality
La qualité des données est assurée par l’implémentation de frameworks dédiés, qui permettent de valider les données, de les documenter et d’automatiser la détection d’anomalies. Ces frameworks aident à détecter et à corriger les problèmes de données en amont, garantissant ainsi que les modèles soient entraînés avec des données fiables et de haute qualité.
Continuous integration
L’intégration continue (CI) est un pilier des pratiques de développement moderne, incluant la vérification des builds, l’exécution de tests à différents niveaux — tests unitaires, tests d’intégration et tests end-to-end — ainsi que l’analyse statique du code (linting). Ces éléments font partie du socle du développement logiciel chez AI Switch. Dans le contexte des systèmes ML, la CI est enrichie par des tests spécifiquement conçus pour les données et la performance prédictive des modèles, comprenant la vérification des schémas de données et l’évaluation de la capacité prédictive des modèles. En intégrant ces étapes de tests dans le processus de CI, nous assurons que le code et les modèles sont continuellement validés et prêts à être déployés.
Continuous deployment
Le déploiement continu doit être spécifiquement adapté pour faire face aux complexités propres aux applications de Machine Learning. En effet, les projets ML se distinguent par la nécessité de gérer simultanément des changements sur trois dimensions distinctes : le code, le modèle et les données. Cette triple exigence confère aux systèmes ML une complexité accrue, requérant l’adoption d’approches de déploiement plus fines et plus réfléchies.
Définir une stratégie de promotion des modèles et automatiser le cycle de vie des applications ML sont essentiels pour réussir à passer à l’échelle. De plus, le monitoring continu des modèles est indispensable pour assurer leur performance et leur pertinence au fil du temps.
Feedback loop
Mettre en place des mécanismes de feedback pour recueillir les retours des utilisateurs finaux et des parties prenantes, et utiliser ces informations pour une amélioration continue des modèles.
Monitoring & Logging
Le monitoring continu des modèles en production est crucial pour identifier rapidement les erreurs et optimiser les modèles. Cette surveillance permet de garantir un haut niveau de performance et facilite la détection et la correction des anomalies.
Notebooks pour la collaboration
Les notebooks jouent un rôle central dans la collaboration et l’expérimentation au sein des projets MLOps. Ils permettent aux data scientists et aux développeurs de partager facilement leurs analyses, leurs codes et leurs résultats, facilitant ainsi la compréhension mutuelle et l’accélération du processus de développement. L’utilisation de notebooks favorise le passage fluide de l’expérimentation à l’industrialisation, en offrant un environnement interactif pour les tests, la visualisation des données, et l’entraînement des modèles. En intégrant ces outils dans vos workflows, les équipes peuvent efficacement documenter leurs progrès et garantir que les connaissances soient accessibles et réutilisables pour l’ensemble de l’organisation.
Archetype & Template
La standardisation via des archétypes et des templates spécifiques aux systèmes ML facilite la création de nouveaux projets et l’onboarding de nouveaux venus. En uniformisant les outils et les pratiques, les équipes peuvent rapidement démarrer des projets avec une base solide.
Interface graphique
Il est important de concevoir des interfaces utilisateurs simples et intuitives durant la phase de prototypage. Elles permettent de démontrer efficacement les capacités des modèles et de faciliter le feedback des utilisateurs. Des outils comme Dash ou Streamlit peuvent être utilisés pour créer rapidement des prototypes interactifs et visuels.
FinOps
La FinOps est une approche stratégique qui permet aux entreprises de gérer efficacement leurs dépenses technologiques. Cette pratique promeut une culture de responsabilité partagée pour les coûts associés à l’utilisation des technologies, de la conception à la maintenance quotidienne. Elle favorise la prise de décisions éclairées, cherchant un équilibre optimal entre le coût, la qualité et l’innovation, en mettant l’accent sur la valeur ajoutée pour l’entreprise.
Dans le contexte spécifique des systèmes ML, elle permet de surveiller précisément le coût des projets, en particulier ceux liés aux entraînements et inférences des modèles nécessitant l’utilisation de GPU coûteux. Cela est crucial pour les projets ML, où les coûts peuvent varier considérablement en fonction de la complexité des modèles et de la fréquence des entraînements.
Cas d'utilisation

Développement d’une stack d’inference sur Kubernetes
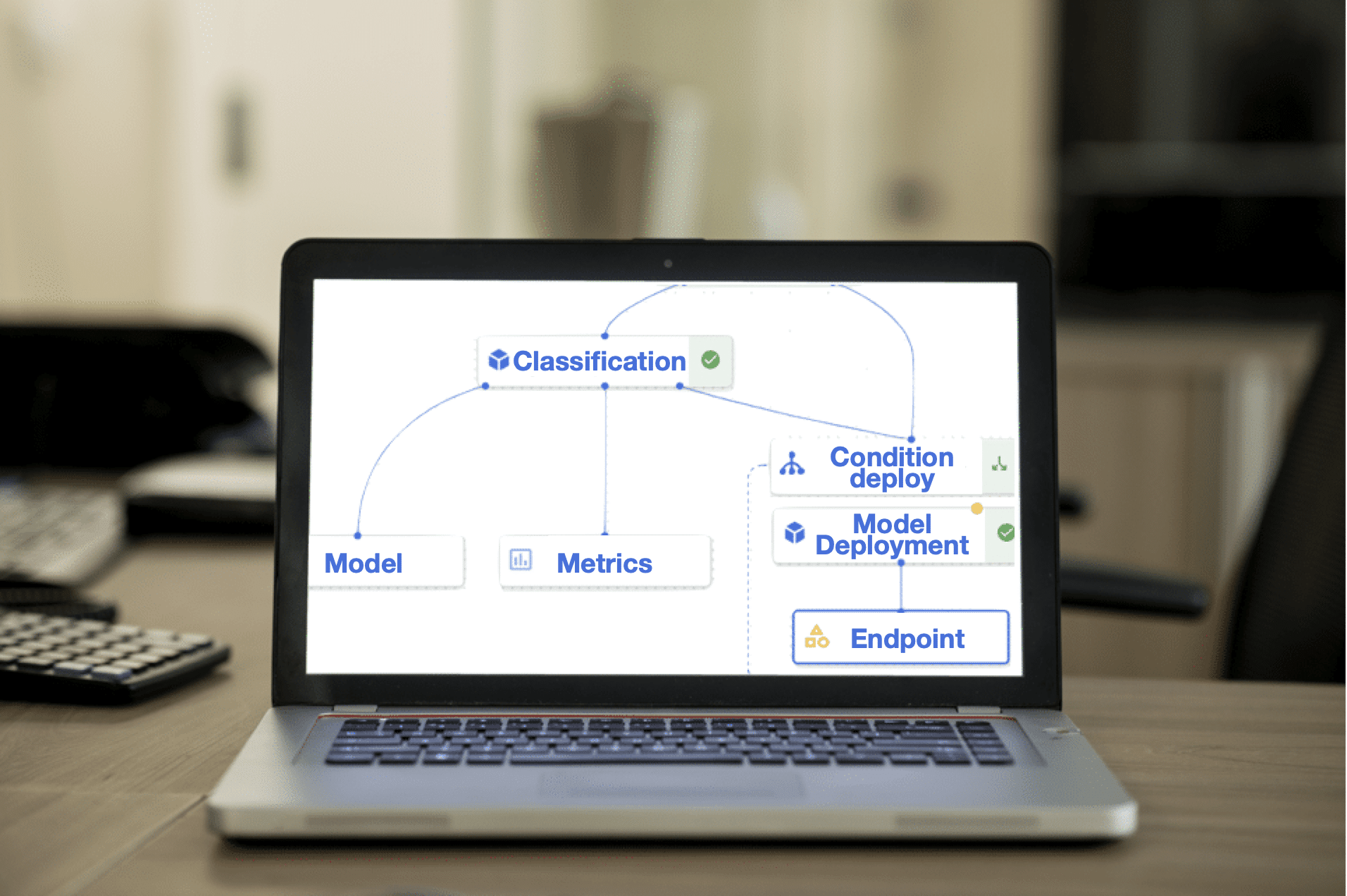
Mise en place d’une stack de training sur GCP
Rencontrez l’équipe MLOps

Radhwane
Expert MLOps et architecte
Radhwane a 10 d’expérience en Machine Learning. Son expérience en freelance dans divers secteurs lui a permis de se construire une expertise reconnue en MLOps et IA Générative.
En plus de sa maitrise technique, Radhwane est calme et consciencieux. Il apporte de la sérénité au sein de nos équipes.

Abdelkader
Fondateur d'AI Switch & Expert en IA
Abdelkader a 10 ans d’expérience dans le monde de l’IA. Il a commencé sa carrière en start-up avant de s’orienter vers le conseil en IA en tant que freelance. Il est aujourd’hui expert en MLOps et en AI Générative.
Par son savoir faire et son grand interêt pour l’IA, Abdelkader a su fédérer nos équipes autour d’une passion commune.